personal blog of Gaurav Ramesh
Sources of Truth - Examining the Nature of Truth in Software
A few weeks ago, while reflecting on the importance of data models in a product, inspired by Matt Brown’s post, Your data model is your destiny, I became convinced that data is the source of truth in software, because at the end of the day, all other things are ephemeral, a giant machinery through which data moves. Data is all that remains.

Then I stumbled upon arguments about three different sources of truth, each pointing to a different artifact: spec, code, and telemetry. Data was conspicuously missing. I could not reconcile the role of data in that triad, so I had to think deeper. One of those articles led me to explore the philosophical nature of truth, which turned out to be a good framework in which to think concretely about the various truths in software development. In the process, I realized another crucial artifact was missing from the picture: tests.
This essay maps truths on two dimensions and then explores where each artifact fits.
Two axes of truth
The first axis is normative vs ontological.
Normative truth is about what ought to be. It's prescriptive. It lives in intent, in desire, in vision, in the gap between the world as it is and the world as we want it. Ontological truth is about what is. It's descriptive. It doesn't care about intent. It's what actually exists or actually happened, independent of the wishes or desires.
The second axis is a priori vs. a posteriori.
A priori truths can be accessed through reason alone and exist before the system runs. A posteriori truths only become available after the system has operated in the world. In other words, some truths can be read from the blueprint, the manual, or found under the hood, without driving the car. Others only emerge when the rubber meets the road.
The two axes are independent. So our software artifacts aren’t arranged on a single line but instead spread across a plane. Any software that produces behavior in the world is going to generate multiple kinds of truth simultaneously, and conflating them is where confusion — and arguments about sources of truth — come from.
Spec as the source of truth
Spec aims to translate customers’ needs into solutions. It’s not perfect – there’s a certain degree of loss and noise introduced in the process, but it’s a best-effort attempt to capture it. Spec, in this case, is not merely the written, textual requirements – what we call the product requirements or the functional requirements, but also the design. Its goal is to specify what the product ought to do, which makes it normative truth. It’s also a priori. You can reason about it before it turns into a piece of software running on a machine.
Because it’s an artifact created by humans for humans, it’s a lossy compression of human intent. It fails both at the points of creation and consumption, almost by design: human intent is inherently unclear and underspecified, and interpretation is subjective. So a spec can make sense, look good and still be wrong.
The spec is like the shadow of a human cast onto paper. It’s a projection. It’s both right and wrong simultaneously, changing depending on the position of the light source and the observer.
In the normative space, this is the most definitive artifact. So when your Product Manager or Designer is talking about what the right behavior should be, this is what they’re really saying.

Code as the source of truth
In this UX Collective article, the author says that code is ontological. It argues that if spec tells you what the system should do, code tells you what it does. On the surface, that seems right. But any engineer who has spent time scratching their head wondering why the system doesn’t do what the code says it does, knows that isn’t quite right.
Code is still prescriptive. It doesn’t describe what the system does. It instructs what it should do. It’s a spec for the machine. Machine normative, if you will, rather than human normative, but normative nonetheless. Like spec, it’s also a priori. You can reason about code in isolation by merely reading it, without running it.
Besides the fact that it operates at a lower level of abstraction, it differs from spec in that it collapses the ambiguity of the spec into determinism. The spec has many valid interpretations; code eliminates all but one. The developer's interpretation of the human spec gets baked in silently. It’s both code’s power and its core failure mode. You can’t see the readings that weren't chosen.

Code, like spec, can be formally correct and still fail to do what the system was meant to do when it meets the metal.
When translating spec to code, during the development process, your operations are largely centered around code. You’re staring at it as you’re understanding it, shaping it, correcting it, validating it, or debugging it. Code reviews, technical design documents, and decision records exist as guardrails to address these failure modes. They are attempts to minimize the loss of translation that happens when going from spec to code.
Which brings us to the third normative artifact.
Tests as the source of truth
Tests sit between spec and code — more formal than spec, more readable than code. They're closer to spec in intent, closer to code in form.
Which is why they inherit code’s failure modes: they can all pass and still fail to do what the spec intended. But by making simple, readable assertions, they surface the developer's chosen interpretation of the spec, making the gap between human intent and machine instruction at least partially visible.

There’s a classic thought experiment that asks if you’d preserve code or tests if you had to choose one. The answer depends on how rigorously the tests cover the intent of the spec, but assuming perfect coverage, tests are what you should preserve, at least according to some. Because, when done right, they’re more intentional about capturing and formalizing the normative truths of the spec.
Telemetry as the source of truth
When code meets the real world, things change. As you go further away from code, especially in a modern distributed system, you introduce all kinds of outside forces that make it hard to reason about the system from looking at code alone: the constraints and state of the machine the code is running in and its inherent non-determinism, neighboring systems contending for the shared pool for resources, dependencies, and the underlying infrastructure of it all. There’s also the manifested behavior when things happen at runtime that the code doesn’t explicitly handle. You can’t see what’s not there.
Which is where telemetry comes into play.
Telemetry captures empirical truth, a kind of ontological truth — what the system actually did, in a given environment, at a given moment. It's the system's manifestation in the world as witnessed. This is the first artifact that requires the system to have run, hence a posteriori.
As you work with a deployed application, your operations become centered around telemetry rather than code. Even when the fault is in code, you arrive at it from telemetry as the starting point. Telemetry provides you the map to make sense of the system, and shrinks the space of possibilities you have to explore in code. When code and telemetry tell you different stories, you trust telemetry.
Its failure mode lies in its completeness: it’s always partial. Instrumentation is always a choice someone made, and even within what’s instrumented, there’s a resolution beyond which telemetry cannot see.
Data tells you a different reality.
Data as the source of truth
Data captures consequential truth, a kind of ontological truth — what the system produced, what now exists as a result of it having run. The key distinction is that data isn't an observation of reality; it is reality, within the system's domain. It’s also a posteriori. It can only exist from the system having run.
There’s a certain indisputable nature to the truthfulness of data. A user's account balance, or a cancelled booking, isn't a signal about what happened — it's what happened, in the only form that matters to anyone outside the system. Unlike telemetry, it doesn't depend on anyone having watched. And because of that, it can’t misrepresent itself. If the data isn’t what you expected, the failure lives somewhere upstream - in the code or in the process that produced it – not in the data itself. To be clear, I’m not saying that the data can’t be wrong, but rather that it’s a record of what the system produced, and there’s no arguing that.
While telemetry is the most grounded truth about the process, data is the most grounded truth about the outcome. Its failure mode is the invisible one: when data and telemetry diverge, it signals that something changed state without being observed. That's the most dangerous class of failure because the system doesn't know what it doesn't know.
Putting it all together
Laid out on the plane, this is how it looks:
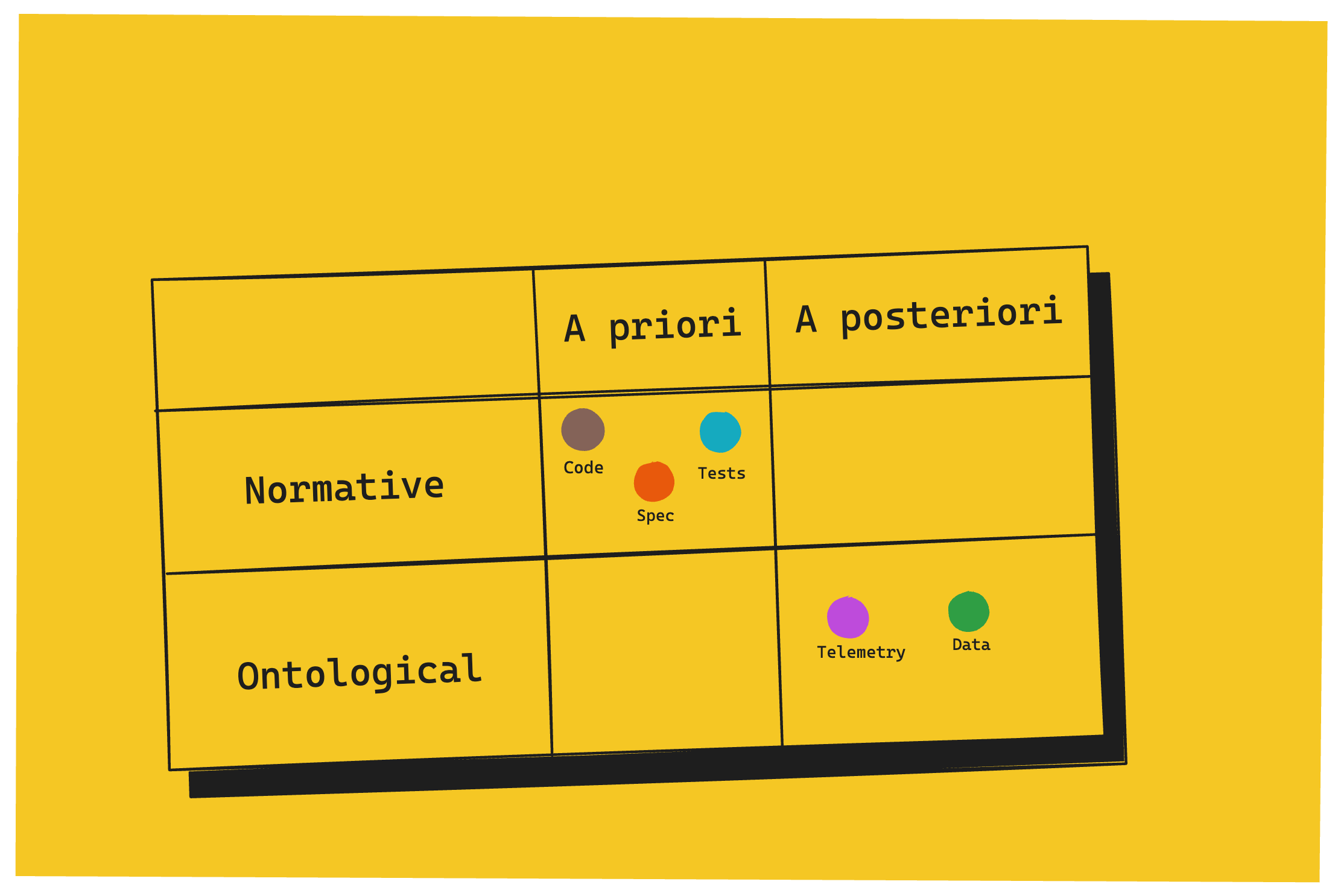
Spec is what we wish for. Data is what we get. Everything in between acts as a way to reduce that gap.
Understanding these distinctions – the nature of the various artifacts, purpose and failure modes – isn’t just an intellectual exercise. It has some interesting implications on how the nature of software development is changing in the age of AI and what that means for those involved in the process of software development. More on that in a subsequent post.
References
Share or Subscribe
Get notified when new posts are published. Once a month, I share thoughtful essays around the themes of personal growth, health & fitness, software, culture, engineering and leadership — all with an occassional philosophical angle.